Auditing Tables
Auditing tables are used to track transactions against a particular table or tables, and sometimes can be used to audit even read-only queries (SELECTS) on your tables (but this is not the subject of this post). SQL Server has an out-of-the-box audit feature, and some other alternatives, however you may prefer a custom solution, where you can have more control and better understanding of the audit tables.
One popular trigger-based solution for this problem is described in this article (with SQL scripts for generating the audit tables (also called shadow tables) and triggers. This solution (from the article) creates one record for each operation (Insert, Update, Delete), obviously with some added columns like the date of the operation, and the user who made the operation. The problem with that design is that it’s difficult to find the state of a particular record at a given time - obviously you can use TOP 1 and ORDER BY to find the state of a single record at any point in time, but that gets difficult when you have to join versioned tables, or even finding a set of records that existed at that given time. So it’s not a good solution for versioning data.
Another problem is that unless your application uses Windows Authentication (or that you are still in 90’s when it was common that each user of client-server applications had dedicated database connections to the database), logging the database user that made the operation is useless - you probably want to know which application user made the operation.
There are other solutions that may (or may not) save some space by tracking only the modified columns, but they also face the same problems that I’ve mentioned earlier.
Personally I believe it’s much better to waste some disk space in favor of something that gives me a better performance and makes daily development easier, because developer’s time is usually much more expensive than disk space.
Data Versioning
When people think about versioning data, they usually think of storing the versioned records in the same table as your main table (where your active records exist). Please don’t. That would radically increase the complexity on your queries in order to make sure the latest version of each record is being used and that you are not duplicating results because of past records. That’s very error-prone. It will also hurt performance of your database. The most common error of versioning in database design is to keep past prices in the same table as current prices. The best place to store past versions of your data is in a separate table.
Similarly, using soft deletes (that famous IsDeleted flag) is a bad idea for the same reasons. The correct place to place your historical data is in a separate report database, and not inside your transactional application. If you understand this design and follow this rule, be careful on what you consider a deleted record: what should be deleted (and possibly moved into your audit/historical table) are records that shouldn’t exist and were created by mistake or similar acts. A duplicate customer is a good example of something that should be deleted, specially because it would force you to either merge the related entities into the correct record or cascade delete them. A batch of accounting entries (posts) that were incorrectly calculated (and were not yet used in your monthly balance or taxes) should be deleted (and should be probably logged into your audit table). A student that is inactive (because he is not enrolled into any courses) should not be deleted.
In general, if an entity can come back to life (like the student) it shouldn’t be deleted (and flagging as inactive is perfectly correct and should not be confused with a soft delete), but if the entity was just wrong and could be recreated somehow (like the accounting entries) or is already created (like versioned records, or like the duplicated customer) then it should be deleted (and not soft deleted, which will cause you more harm than good). A good smell that you are incorrectly using soft deletes is when your application button says “Delete” and you are not really deleting. If you just inactivating the record, probably the button should reflect that.
In summary, your transactional tables should keep only active data - not deleted records, and not past revisions. Don’t be lazy: create new tables (and new CRUDs) for historical data - It will take you a few minutes but will save you countless hours later, so I’m sure it’s a good investment.
Let’s kill two birds with a stone, and use audit tables also for versioning data
Since Versioning Tables and Audit Tables have much in common, I decided that I would use a single structure for both. And that led me to make a few changes in the triggers/audit tables from this article.
This is my proposed design for audit-tables:
- Like other solutions, each audit table has the same columns as the audited table, but a new identity primary key.
- For tracking the user who made an operation I keep both ID (int) and Username (varchar) columns. When I can identify the application user I have both his ID and his Name or Login. When I can’t identify the user who is doing the transaction (when something happens outside the application) I track the SQL user that was used, his hostname and IP.
- Each audit row has both columns for tracking when that record revision started existing (it could be either a new record, or modified from a previous state), and also for tracking when that record revision stopped existing (it could be either a deleted record, or modified to a newer state).
- AuditStartDate tracks the starting moment of the record revision, AuditEndDate tracks the ending moment for that revision.
- AuditStartUserID, AuditStartUserName, AuditEndUserID and AuditEndUserName are the User ID and User Name that respectively put the record into that state and the one that removed the record from that state.
- AuditStartOperation is I (INSERTED) if the tracked record is new (first revision) or U (UPDATED) if the tracked record already existed before and was just updated.
- AuditEndOperation is D (DELETED) if the tracked record ceased existing because it was deleted, or U if the tracked record just was updated to a new state.
- AuditStartTransactionGUID and AuditEndTransactionGUID are just unique identifiers that I use to know which operations happened in the same transaction, and mostly for connecting the previous state of a record to the next state. (more on that later).
- As you may have noticed, I don’t have RevisionID for numbering the revisions of each record. That would force me to refer to the audit table itself, and maybe it could even generate some deadlocks. I just decided that I don’t need it. I can renumber my audit records whenever I need.
A visual example to make things clear
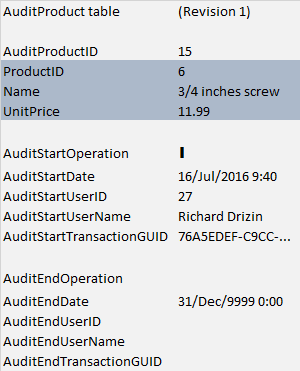
Richard Drizin created the product.
When some record is created, the auditing table will create a record which will track all the information that was inserted into the audited table (highlighted fields in screenshot), and will also add some tracking information (non-highlighted fields) that contain the operation (Insert), the date when it was inserted, and the user who inserted.
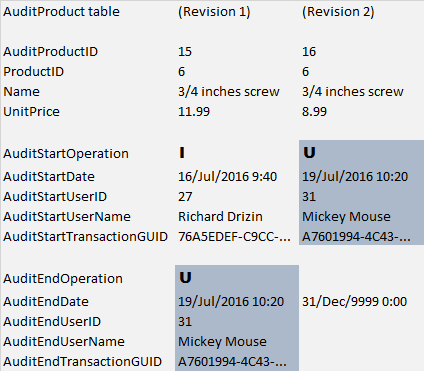
Mickey Mouse updated the product (changed the unit price).
When some record is updated, the auditing table will create a new record which will track the new state for the record, and should also mark that the previous revision is not valid anymore. The highlighted fields on the top-right are tracking information for the new revision, which is the same tracking information that is used for updating the end-of-life of the previous revision (highlighted on bottom left).
Please note that the date and the transaction which were used on the new revision are exactly the same that were used for marking the end of the lifetime of the past revision - this gives you an easy and elegant way to link the previous state to the new state, and using the exact same datetime is important to have contiguous time periods. Also note that the EndOperation of revision 1 was marked as “U” since that revision was not deleted, but updated into a new state.
Donald Duck deleted the product.
When some record is deleted, no new revisions are created, however the previous active revision must be marked to inform that it’s not valid anymore. The highlighted fields are the ones which were updated in previous revision, and show the user who deleted, and the deletion date.

Queries will be as simple as this:
-- To find the ACTIVE version
SELECT * FROM [Audit_Products] WHERE GETDATE() BETWEEN AuditStartDate AND AuditEndDate
-- To find the version that existed at any given time
SELECT * FROM [Audit_Products] WHERE @SomeDate BETWEEN AuditStartDate AND AuditEndDate.
-- AuditEndOperation would indicate if that version is still active (NULL), if it was DELETED ('D') or if it was somehow UPDATED ('U')
-- To find the first version
SELECT * FROM [Audit_Products] WHERE AuditStartOperation='I'
-- To find the last version (even if deleted)
SELECT * FROM [Audit_Products] WHERE AuditEndDate='9999-12-31' OR AuditEndOperation='D'
Please note that some of those queries suppose that you are using surrogate keys, which guarantee that under normal conditions each key will have only one insert and at most one delete. And afterall, using surrogate keys is almost always (if not always) a good choice.
Please also note that SQL BETWEEN is INCLUSIVE, so if you use BETWEEN it is possible (although very unlikely, because you would have to search for the exact moment that some record was updated) that you get 2 different revisions.
I used BETWEEN to make the article easier to understand, but when searching for the state of records in a past point in time it’s safer to use half-open interval [AuditStartDate, AuditEndDate) : @SomeDate >= AuditStartDate AND @SomeDate < AuditEndDate.
Also, please note that if you run GETDATE() >= AuditStartDate AND GETDATE()< AuditEndDate you could still have problems, because each time you run GETDATE() (even in a single statement) could lead to a different value. But if you want to get current records instead of using GETDATE() you can also check for the AuditEndOperation.
So in summary these are fail-proof queries:
-- To find the ACTIVE version
SELECT * FROM [Audit_Products] WHERE AuditEndOperation IS NULL
-- To find the version that existed at any given time
SELECT * FROM [Audit_Products] WHERE @SomeDate>=AuditStartDate AND @SomeDate<AuditEndDate.
-- AuditEndOperation would indicate if that version is still active (NULL), if it was DELETED ('D') or if it was somehow UPDATED ('U')
-- To find the first version
SELECT * FROM [Audit_Products] WHERE AuditStartOperation='I'
-- To find the last version (even if deleted)
SELECT * FROM [Audit_Products] WHERE AuditEndDate='9999-12-31' OR AuditEndOperation='D'
-- or even
SELECT * FROM [Audit_Products] WHERE AuditEndOperation IS NULL OR AuditEndOperation='D'
The implementation
For tracking in your tables which system user (and not database user) made an operation, you must somehow pass that information from your application to your database connection. At first I was using SQL Context Info for passing information about the current logged user, but then I decided to use temporary tables for that, to avoid the complexity of binary serialization. This is how I pass information to my triggers:
CREATE PROCEDURE [dbo].[sp_SetContextInfo]
@UserID INT,
@Username varchar(128) = NULL
AS
BEGIN
CREATE TABLE #session ([Username] varchar(128), [UserID] int NOT NULL)
INSERT INTO #session VALUES (@Username, @UserID)
END
This is how I receive information from my triggers:
CREATE PROCEDURE [dbo].[sp_GetContextInfo]
@UserID INT OUTPUT,
@Username varchar(128) OUTPUT,
@TransactionGUID UNIQUEIDENTIFIER OUTPUT
AS
BEGIN
SET @UserID = 0
SET @Username = NULL
SET @TransactionGUID = NEWID()
IF OBJECT_ID('tempdb..#session') IS NOT NULL BEGIN -- Get @Username and @UserID given by the application
SELECT @Username = Username, @UserID = COALESCE(UserID, 0), @TransactionGUID = COALESCE(TransactionGUID, NEWID())
FROM #session
END
IF (@Username IS NULL) -- if no application user was given, get sql user, hostname and ip
SELECT @Username = '[' + SYSTEM_USER + '] ' + RTRIM(CAST(hostname AS VARCHAR))
+ ' (' + RTRIM(CAST(CONNECTIONPROPERTY('client_net_address') AS VARCHAR)) + ')'
from master..sysprocesses where spid = @@spid
END
This is how I pass information about the current user to the database connections (using C# and Entity Framework 6), so that every change can be tracked down to the correct user:
namespace NorthwindAudit
{
partial class NorthwindAuditDB
{
/// <summary>
/// Currently logged user that is using the connection. For auditing purposes.
/// </summary>
public string Username { get; set; }
/// <summary>
/// Currently logged user that is using the connection. For auditing purposes.
/// </summary>
public int UserID { get; set; }
// modify your constructor to force developer to pass the username and userid.
public NorthwindAuditDB(string Username, int UserID) : this()
{
this.Username = Username;
this.UserID = UserID;
this.Configuration.LazyLoadingEnabled = true;
// you may want to disable this if you have some batch jobs that dont run on users context... but I like to enforce that caller always provide some user
if (this.UserID == 0 || this.Username == null)
throw new ArgumentNullException("You must provide the application user, for auditing purposes");
this.Database.Connection.StateChange += new System.Data.StateChangeEventHandler(Connection_StateChange);
}
//pass the application user to the SQL when the connection opens (because the connection could already have been used by another DbContext)
void Connection_StateChange(object sender, System.Data.StateChangeEventArgs e)
{
// State changed to Open
if (e.CurrentState == ConnectionState.Open && e.OriginalState != ConnectionState.Open)
{
SetConnectionUser(this.UserID, this.Username);
}
}
void SetConnectionUser(int userID, string username)
{
// Create local temporary context table
var cmd = this.Database.Connection.CreateCommand();
cmd.CommandText = "IF OBJECT_ID('tempdb..#session') IS NOT NULL DROP TABLE #session";
cmd.ExecuteNonQuery();
if (userID != 0 && username != null)
{
cmd.CommandText = "CREATE TABLE #session ([Username] varchar(128), [UserID] int NOT NULL, [TransactionGUID] UNIQUEIDENTIFIER NOT NULL)";
cmd.ExecuteNonQuery();
cmd.CommandText = "INSERT INTO #session ([Username], [UserID], [TransactionGUID]) VALUES (@Username, @UserID, NEWID())";
cmd.Parameters.Add(new SqlParameter("@UserID", userID));
cmd.Parameters.Add(new SqlParameter("@Username", username ?? ""));
cmd.ExecuteNonQuery();
}
}
// This probably is not necessary, but I like to check that the session table matches the provided user.
// I haven't made stress testing for concurrency issues, so better safe than sorry.
public override int SaveChanges()
{
if (this.UserID == 0 || this.Username == null)
throw new ArgumentNullException("You must provide a user for the connection, for auditing purposes");
#region Just in case! Double checking that table #session was created and that it matches the user for the context
bool wasClosed = false;
if (this.Database.Connection.State == ConnectionState.Closed)
{
this.Database.Connection.Open();
wasClosed = true;
}
var cmd = this.Database.Connection.CreateCommand();
cmd.CommandText = "EXEC [dbo].[sp_GetContextInfo] @UserID OUTPUT, @Username OUTPUT, @TransactionGUID OUTPUT";
var parm1 = new SqlParameter("@UserID", SqlDbType.Int); parm1.Direction = ParameterDirection.Output; cmd.Parameters.Add(parm1);
var parm2 = new SqlParameter("@Username", SqlDbType.VarChar, 128); parm2.Direction = ParameterDirection.Output; cmd.Parameters.Add(parm2);
var parm3 = new SqlParameter("@TransactionGUID", SqlDbType.UniqueIdentifier); parm3.Direction = ParameterDirection.Output; cmd.Parameters.Add(parm3);
//Error: ExecuteNonQuery requires an open and available Connection
//http://stackoverflow.com/questions/7201754/executenonquery-requires-an-open-and-available-connection-the-connections-curr
cmd.ExecuteNonQuery();
if (wasClosed)
this.Database.Connection.Close();
if (parm1.Value == null || ((int)parm1.Value) == 0 || parm2.Value == null || string.IsNullOrEmpty((string)parm2.Value))
throw new ArgumentNullException("You must provide a user for the connection, for auditing purposes");
if (((int)parm1.Value) != this.UserID || ((string)parm2.Value) != this.Username)
throw new ArgumentNullException("The user provided in #session table does not match the user provided on the connection (DbContext)");
#endregion
return base.SaveChanges();
}
}
}
This is a sample of Audit Table for Northwind Orders table:
SET ANSI_NULLS ON
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [audit].[Audit_dboProducts](
[Audit_dboProductsID] [int] IDENTITY(1,1) NOT NULL,
[ProductID] [int] NOT NULL,
[CategoryID] [int] NULL,
[Discontinued] [bit] NOT NULL,
[ProductName] [nvarchar](40) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[QuantityPerUnit] [nvarchar](20) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[ReorderLevel] [smallint] NULL,
[SupplierID] [int] NULL,
[UnitPrice] [money] NULL,
[UnitsInStock] [smallint] NULL,
[UnitsOnOrder] [smallint] NULL,
[AuditStartDate] [datetime] NOT NULL,
[AuditEndDate] [datetime] NOT NULL,
[AuditStartOperation] [char](1) COLLATE Latin1_General_CI_AS NOT NULL,
[AuditEndOperation] [char](1) COLLATE Latin1_General_CI_AS NULL,
[AuditStartUserID] [int] NOT NULL,
[AuditStartUsername] [varchar](128) COLLATE Latin1_General_CI_AS NOT NULL,
[AuditEndUserID] [int] NULL,
[AuditEndUsername] [varchar](128) COLLATE Latin1_General_CI_AS NULL,
[AuditStartTransactionGUID] [uniqueidentifier] NOT NULL,
[AuditEndTransactionGUID] [uniqueidentifier] NULL,
PRIMARY KEY CLUSTERED
(
[Audit_dboProductsID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON)
)
GO
This is a sample of Audit Trigger for Northwind Orders table:
SET ANSI_NULLS ON
SET QUOTED_IDENTIFIER ON
GO
ALTER TRIGGER [dbo].[trAuditProducts] ON [dbo].[Products]
WITH EXECUTE AS 'audituser'
FOR INSERT, UPDATE, DELETE
AS
SET NOCOUNT ON -- Trigger cannot affect the "rows affected" counter, or else it would break Entity Framework
-- Logged User
DECLARE @UserID INT
DECLARE @Username varchar(128)
DECLARE @Now datetime
DECLARE @TransactionGUID UNIQUEIDENTIFIER
EXEC [dbo].[sp_GetContextInfo] @UserID OUTPUT, @Username OUTPUT, @TransactionGUID OUTPUT
DECLARE @infinite DATETIME
SET @infinite = '9999-12-31'
-- InsertUpdate
DECLARE @Action varchar(1)
SET @Action = 'D'
-- Defining if it's an UPDATE (U), INSERT (I), or DELETE ('D')
IF (SELECT COUNT(*) FROM inserted) > 0 BEGIN
IF (SELECT COUNT(*) FROM deleted) > 0
SET @Action = 'U'
ELSE
SET @Action = 'I'
END
SET @Now = GETDATE()
-- Closing the lifetime of the current revisions (EndDate=infinite) for records which were updated or deleted
IF (@Action='D' OR @Action='U')
UPDATE [audit].[Audit_dboProducts]
SET [AuditEndDate] = @Now,
[AuditEndUserID] = @UserID,
[AuditEndUsername] = @Username,
[AuditEndTransactionGUID] = @TransactionGUID,
[AuditEndOperation] = @Action
FROM [audit].[Audit_dboProducts] aud
INNER JOIN deleted tab
ON [tab].[ProductID] = [aud].[ProductID]
AND aud.[AuditEndDate] = @infinite
-- Creating new revisions for records which were inserted or updated
IF (@Action='I' OR @Action='U') BEGIN
INSERT INTO [audit].[Audit_dboProducts] ([ProductID], [ProductName], [SupplierID], [CategoryID], [QuantityPerUnit], [UnitPrice], [UnitsInStock], [UnitsOnOrder], [ReorderLevel], [Discontinued], [AuditStartDate], [AuditEndDate], [AuditStartOperation], [AuditStartUserID], [AuditStartUsername], [AuditStartTransactionGUID])
SELECT [inserted].[ProductID], [inserted].[ProductName], [inserted].[SupplierID], [inserted].[CategoryID], [inserted].[QuantityPerUnit], [inserted].[UnitPrice], [inserted].[UnitsInStock], [inserted].[UnitsOnOrder], [inserted].[ReorderLevel], [inserted].[Discontinued],
@Now,
@infinite,
@Action,
@UserID,
@Username,
@TransactionGUID
FROM inserted
END
GO
Let’s try another test on Northwind database:
static void Main(string[] args)
{
// creating product, order and orderitem
var db = new NorthwindAuditDB("Richard Drizin", 27);
var product = new Product()
{
ProductName = "3/4 inches screw",
UnitPrice = 9.99m,
UnitsInStock = 23
};
var order = new Order()
{
CustomerID = "FRANK", // Customers PK is varchar in Northwind ... yeah I know
EmployeeID = 1,
OrderDate = DateTime.Now,
};
order.Order_Details.Add(new Order_Detail()
{
Product = product,
UnitPrice = product.UnitPrice.Value,
Quantity = 3,
});
db.Orders.Add(order);
db.SaveChanges();
// updating quantity of items
db = new NorthwindAuditDB("Mickey Mouse", 31);
var lastOrder = db.Orders.Where(x => x.CustomerID == "FRANK").OrderByDescending(x=>x.OrderID).First();
lastOrder.Order_Details.First().Quantity++;
db.SaveChanges();
// deleting order and orderitem
db = new NorthwindAuditDB("Donald Duck", 33);
var lastOrder2 = db.Orders.Where(x => x.CustomerID == "FRANK").OrderByDescending(x => x.OrderID).First();
db.Order_Detail.RemoveRange(lastOrder2.Order_Details);
db.Orders.Remove(lastOrder2);
db.SaveChanges();
}
Results:
Product was created once, never modified or deleted. (I’ve hidden null columns so the screenshot could fit the article):

Order was inserted, and later deleted (it’s a single row, but I made it vertical so the screenshot could fit the article):

Order item was inserted, updated, and later deleted. (there are 2 rows, but I made it vertical so the screenshot could fit the article):
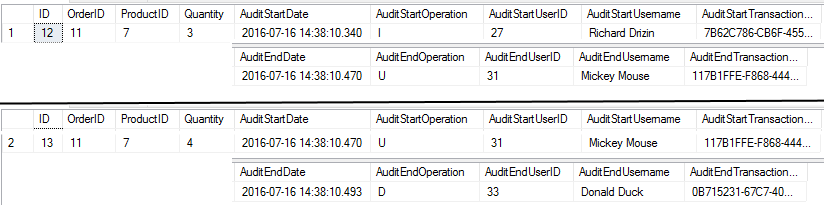
If I manually update (on SQL Management Studio) the table, it will track the SQL user, Hostname an IP:

Last comments and some advanced techniques:
- You can create the AUDIT tables on a separate file group (because of growth?). However that will give you the freedom to restore audit tables individually, and I think it is more dangerous than helpful.
- I created the AUDIT tables under a different schema, so the triggers must run “WITH EXECUTE AS” on some user which has permission on that schema. The regular database user for my application cannot access the auditing tables.
- Instead of using “infinite” you could use NULL. I prefer to leave infinite so that my queries can use BETWEEN instead of checking for nulls or using COALESCE.
- You cannot use text, ntext, or image columns in the ‘inserted’ tables. You can circumvent that by looking for the data in the real table, since the trigger runs after the insert/update happens. Just join the inserted with the real table, and refer to those columns on the real table.
- For the updates I’m not checking if something really changed. I really don’t need it because Entity Framework only sends updates when something was really changed. If you need to check for modifications (with small performance penalty) you can also join the inserted table with the real table, and only insert when something was modified.
- For updates you could also track only changed columns by keeping NULLs on every UPDATE that didn’t modify that column, but then for a nullable column you wouldn’t be able to tell when it’s a NULL or when it was a “not modified”. Even for non-nullable columns I still don’t think it’s worth - I prefer to have a simple and homogeneous design, in the sense that the audit tables reflect the exact same state as my transactional tables. If I need to make a human-readable log of what’s changed that’s responsibility of another algorithm, and not responsibility of the table.
- I’m tracking modifications on every column. Again, I prefer to have a simple and homogeneous solution better than saving some disk space.